
Lab 2 - Math 178, Spring 2024#
You are encouraged to work in groups of up to 3 total students, but each student should submit their own file. (It’s fine for everyone in the group to submit the same link.)
Put the full names of everyone in your group (even if you’re working alone) here. This makes grading easier.
Names:
The attached data is a very slightly altered form of this Kaggle dataset.
Read in the attached credit card fraud data and look at its contents. Pay particular attention to the column data types. In this lab, we are interested in predicting the contents of the “fraud” column.
Preparing the data#
Divide the data into a training set and a test set. Specify a random_state when you call train_test_split, so that you get consistent results. I had trouble in the logistic regression section if my training set was too big, so I recommend using only 10% of the data (still a lot, 100,000 rows) as the training size. It’s possible that using even a smaller training size is appropriate.
Imagine we always predict “Not Fraud”. What accuracy score (i.e., proportion correctly classified) do we get on the training set? On the test set? Why can there not be any overfitting here?
Logistic regression - using scikit-learn#
Fit a scikit-learn LogisticRegression classification model to the training data. Because it is such a large dataset, I ran into errors/warnings during the fit stage if I had instantiated the LogisticRegression object using the default parameters. To combat this, I used only 10% of the data in my training set, I increased the default number of iterations, and I changed the solver. You can see the options in the LogisticRegression class documentation. Originally I also increased the default tolerance, but it seems like this makes the model less accurate, so try to avoid increasing the tolerance if possible. Don’t be surprised if fitting the model takes up to 5 minutes. If you’re having issues, try increasing the tolerance very slightly.
What is the accuracy score on the training set? On the test set? Are you concerned about overfitting?
Evaluate the scikit-learn
confusion_matrixfunction on the test data (documentation). Which entry in this confusion matrix would you focus the most on, if you were a bank? Why?
Naive Bayes - by hand#
Our goal in this section is to perform Naive Bayes “by hand” (or at least without using a scikit-learn model). Recall that Naive Bayes is based on the following formula, taken from Section 4.4 of ISLP:
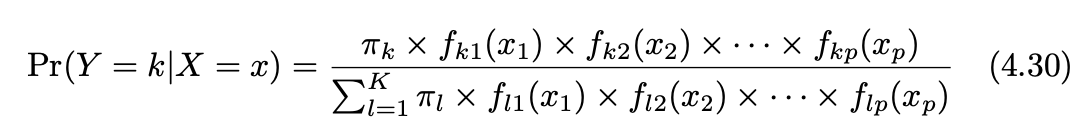
In our case, \(k\) will represent either “Fraud” or “Not Fraud”. The function \(f_{ki}(x_i)\) represents the probability (or probability density) of the i-th predictor being \(x_i\) in class \(k\). To estimate these functions \(f_{ki}\), we will use the first and third bullet points beneath Equation (4.30) in ISLP, according to whether the variable is a float type or a Boolean type. The term \(\pi_k\) represents prior probability of class \(k\) (prior meaning without dependence on the predictors \(x_i\)).
Strategy:
We first compute the values \(\pi_k\).
We then (prepare to) compute the functions \(f_{ki}\) when \(i\) represents a float column.
We then (prepare to) compute the functions \(f_{ki}\) when \(i\) represents a Boolean column.
Define a dictionary
prior_dctrepresenting the two prior values \(\pi_{Fraud}\) and \(\pi_{Not Fraud}\), as in the following template.
prior_dct = {
"Fraud": ???,
"Not Fraud": ???
}
Reality check: the two values should sum to (approximately) 1.
It’s temporarily convenient here to have
X_trainandy_traintogether in the same DataFrame. Concatenate these together along the columns axis and name the resultdf_train.
Write a function
Gaussian_helperwhich takes a DataFrame inputdfand two string inputs, a classk(which will be “Not Fraud” or “Fraud” in our case) and a column namecolof one of the float columns. The output should be a dictionary with keys"mean"and"std", representing the mean and the standard deviation for the given column within the given class, as in the first bullet point after (4.30).
Comment: To find the mean and standard deviation, you can use the formulas in (4.20) (take the square root of the variance to get the standard deviation), but I think it’s easier to just let pandas compute these for you, using the mean and std methods of a pandas Series. It’s possible pandas will use \(n\) instead of the \(n-K\) in Equation (4.20), but that shouldn’t be significant here because \(n\) is so big and \(K=2\).
Here is a possible template:
def Gaussian_helper(df, k, col):
output_dct = {}
... # one or more lines here
output_dct["mean"] = ...
output_dct["std"] = ...
return output_dct
Similarly, write a function
Boolean_helperwhich takes a DataFrame inputdfand two string inputs, a classk(which will be “Not Fraud” or “Fraud” in our case) and a column namecolof one of the Boolean columns. The output should be a dictionary with keysTrueandFalse, representing the proportion of these values within the given class. For an example, see the third bullet point after (4.30) in the textbook.
Comment: Make sure your keys are bool values, not strings.
Check your helper functions by comparing a few of their outputs to the following. (I feel like there is probably a nice way to use the following DataFrame directly and never define the helper functions, but I did not succeed in doing that.)
df_train.groupby("fraud").mean()
Here is an example of applying the Gaussian probability density function with mean 10 and standard deviation 4 to every entry in a column, without explicitly using any loops.
from scipy.stats import norm
norm.pdf(X_train["distance_from_last_transaction"], loc=10, scale=4)
You should view the outputs as representing the probability (densities) of the given Gaussian distribution producing the input values.
Here is an example of using a dictionary to replace every value in a column. Think of the values in this dictionary as our estimated probabilities.
temp_dct = {True: 0.71, False: 0.29}
X_train["used_chip"].map(temp_dct)
Momentarily fix the class \(k\) to be “Fraud”. We are going to compute the numerator of Equation (4.30) for every row of X_train. (Here we switch back to using X_train rather than df_train.)
Do all of the following in a single code cell. (The reason for not separating the cells is so that the entire cell can be run again easily.)
Assign
k = "Fraud".Copy the
X_trainDataFrame into a new DataFrame calledX_temp. Use thecopymethod.For each column of
X_temp, useGaussian_helperorBoolean_helper, as appropriate, to replace each value \(x_i\) with \(f(x_i)\), where \(f\) is as in (4.30). You can use a for loop to loop over the columns, but within a fixed column, you should not need to use a for loop (in other words, you should not need to loop over the rows, only over the columns). The following imports might be helpful for determining the data types (make the imports outside of any for loop).
from pandas.api.types import is_bool_dtype, is_float_dtype
Comment: Your code should be changing the X_temp entries but not the X_train entries. When you are finished, X_temp will be a DataFrame containing probabilities, all corresponding to the “Fraud” class.
For each row, multiply all entries in that row. (Hint. DataFrames have a
prodmethod.) Also multiply by the prior probability of “Fraud”. (Usek, do not type"Fraud".) The end result should be a pandas Series corresponding to the numerator of (4.30), for each row ofX_train. Don’t be surprised if the numbers are very small, like around \(10^{-10}\).
Once the code is working, wrap the whole thing into another for loop, corresponding to
k = "Fraud"andk = "Not Fraud", putting the two resulting pandas Series into a length 2 dictionary with keys"Fraud"and"Not Fraud". Call this dictionarynum_dct, because it represents the numerators of (4.30).
Create a new two-column pandas DataFrame with the results using the following code:
df_num = pd.DataFrame(num_dct)
What proportion of the values in
X_trainare correctly identified as Fraud using this procedure? (Note. We never actually need to compute the denominator in (4.30), since all we care about here is which entry is bigger.)
Submission#
Using the
Sharebutton at the top right, enable public sharing, and enable Comment privileges. Then submit the created link on Canvas.
Possible extensions#
I originally wanted us to consider log loss as our error metric, but I decided the lab was already getting rather long, so I removed that. But in general, log loss is a more refined measure for detecting overfitting than accuracy score. It should be relatively straightforward to evaluate log loss for the Logistic Regression model. Compare this to the log loss of a baseline prediction, where we predict the same probability for every row. I got some errors when I tried to evaluate log loss for the Naive Bayes model and I haven’t thought carefully about how to avoid these.
How do our values compare to using the scikit-learn Naive Bayes model? (I don’t think this will be easy, because you will have to treat the Gaussian and the Boolean portions separately. There might also be some discrepancy due to our method of estimating standard deviation, but I don’t think that is crucial. I have not tried this myself, so there could also be other discrepancies I’m not anticipating.)
How does KNN compare in performance? (What’s the optimal number of neighbors?) I haven’t tried this, and I think the training size might be too large, so be prepared to reduce the size of the training set further.
 Created in Deepnote
Created in Deepnote