Week 8 Video notebooks
Contents
Week 8 Video notebooks¶
import numpy as np
import torch
from torch import nn
from torchvision.transforms import ToTensor
A little neural network¶
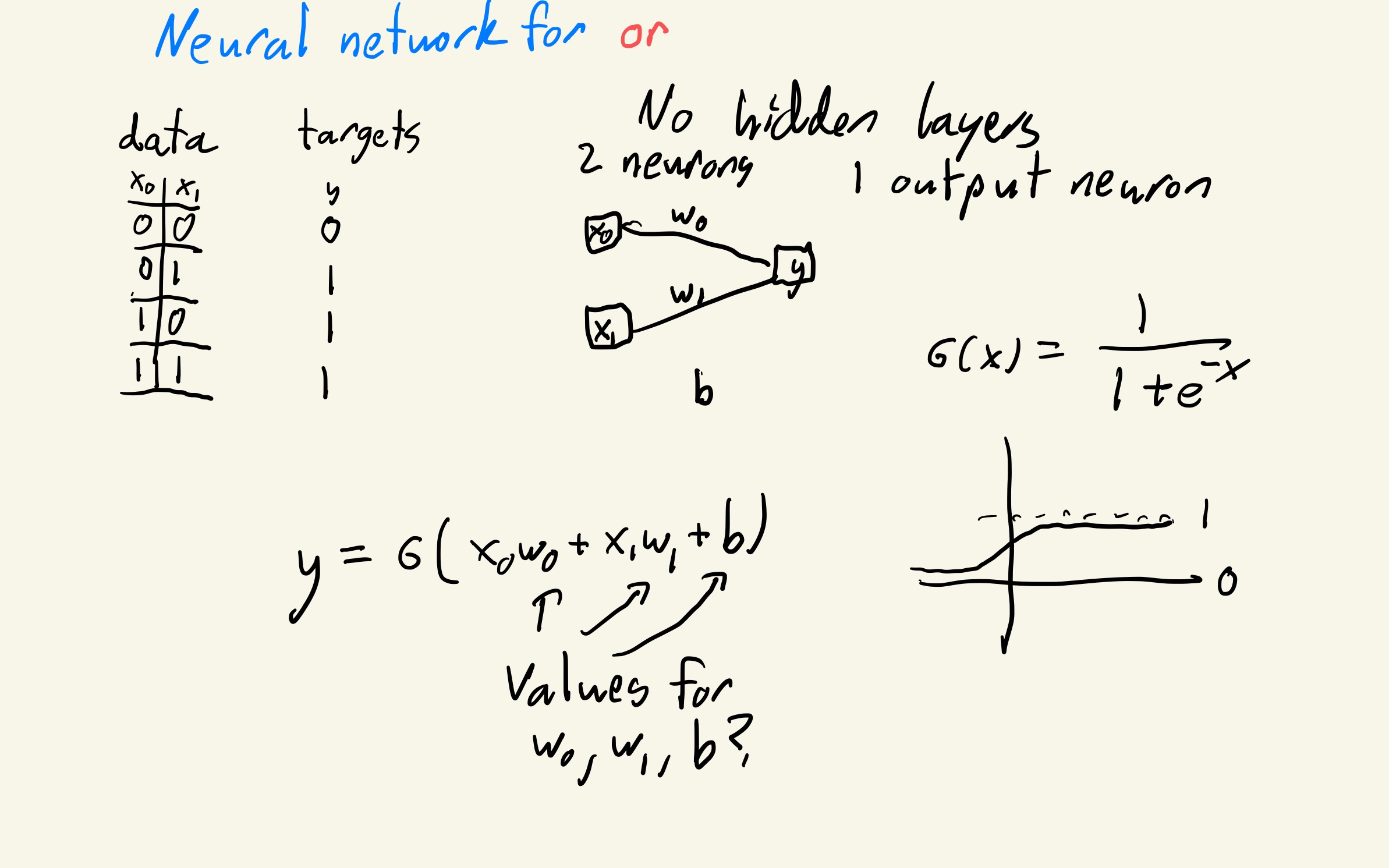
Neural network for logical or¶
X = torch.tensor([[0,0],[0,1],[1,0],[1,1]]).to(torch.float)
y = torch.tensor([0,1,1,1]).to(torch.float).reshape(-1,1)
class LogicOr(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(2,1),
nn.Sigmoid()
)
def forward(self,x):
return self.layers(x)
model = LogicOr()
model(X)
tensor([[0.4466],
[0.4217],
[0.5070],
[0.4816]], grad_fn=<SigmoidBackward0>)
for p in model.parameters():
print(p)
Parameter containing:
tensor([[ 0.2424, -0.1016]], requires_grad=True)
Parameter containing:
tensor([-0.2143], requires_grad=True)
Evaluating our neural network¶
loss_fn = nn.BCELoss()
y.shape
torch.Size([4, 1])
loss_fn(model(X),y)
tensor(0.7162, grad_fn=<BinaryCrossEntropyBackward0>)
Optimizer¶
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for p in model.parameters():
print(p)
print(p.grad)
print("")
Parameter containing:
tensor([[ 0.2424, -0.1016]], requires_grad=True)
None
Parameter containing:
tensor([-0.2143], requires_grad=True)
None
loss = loss_fn(model(X),y)
optimizer.zero_grad()
loss.backward()
for p in model.parameters():
print(p)
print(p.grad)
print("")
Parameter containing:
tensor([[ 0.2424, -0.1016]], requires_grad=True)
tensor([[-0.2528, -0.2742]])
Parameter containing:
tensor([-0.2143], requires_grad=True)
tensor([-0.2857])
optimizer.step()
for p in model.parameters():
print(p)
print(p.grad)
print("")
Parameter containing:
tensor([[ 0.2677, -0.0741]], requires_grad=True)
tensor([[-0.2528, -0.2742]])
Parameter containing:
tensor([-0.1857], requires_grad=True)
tensor([-0.2857])
Training the model¶
100%50
0
epochs = 1000
for i in range(epochs):
loss = loss_fn(model(X),y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%50 == 0:
print(loss)
tensor(0.6946, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.3871, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.3277, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.2883, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.2573, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.2318, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.2107, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1929, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1777, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1645, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1531, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1431, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1342, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1263, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1192, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1128, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1071, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.1018, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0971, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0927, grad_fn=<BinaryCrossEntropyBackward0>)
epochs = 1000
for i in range(epochs):
loss = loss_fn(model(X),y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%100 == 0:
print(loss)
epochs = 1000
for i in range(epochs):
loss = loss_fn(model(X),y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%100 == 0:
print(loss)
tensor(0.0468, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0446, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0426, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0408, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0392, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0376, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0362, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0349, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0336, grad_fn=<BinaryCrossEntropyBackward0>)
tensor(0.0325, grad_fn=<BinaryCrossEntropyBackward0>)
for p in model.parameters():
print(p)
print(p.grad)
print("")
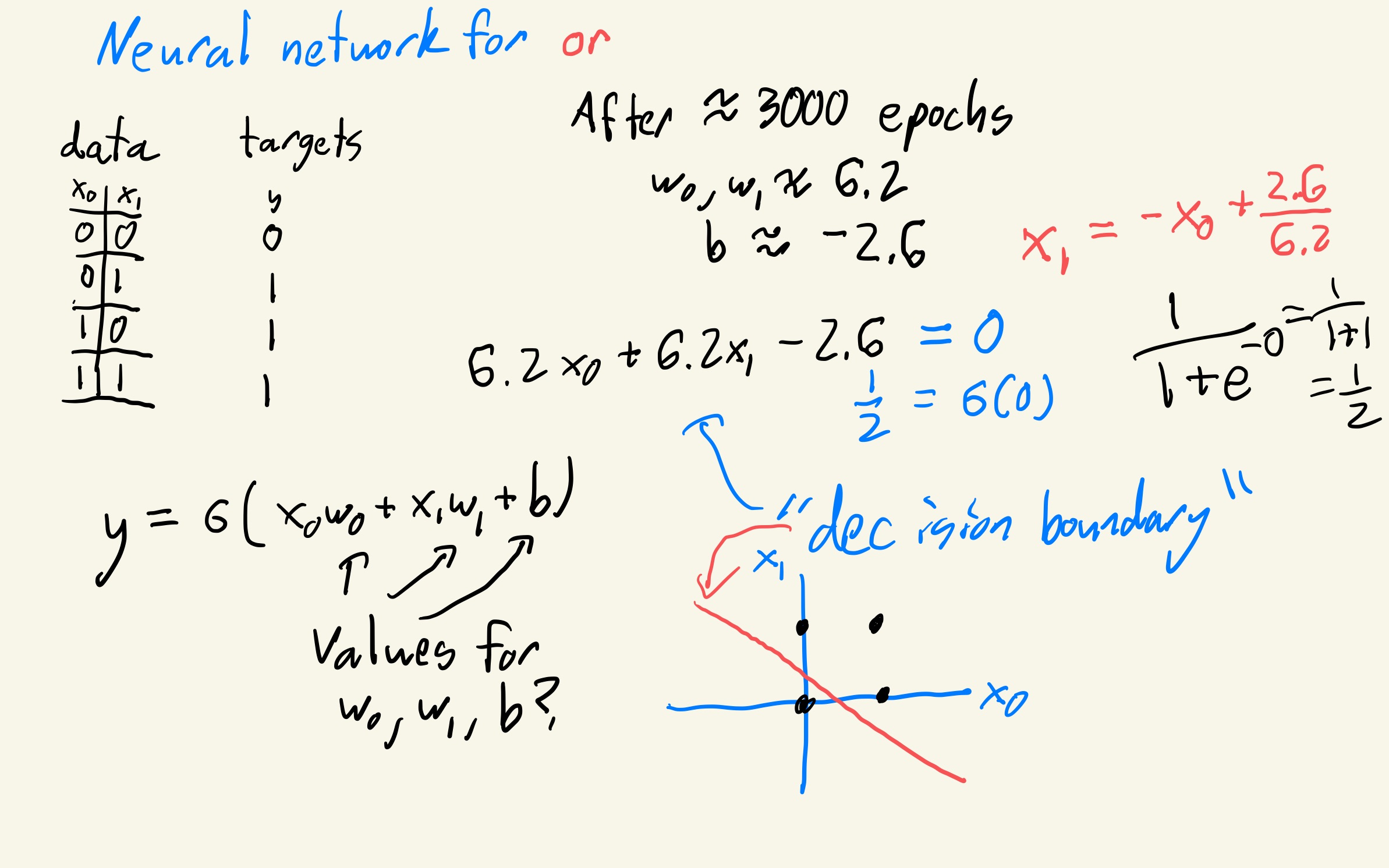
Parameter containing:
tensor([[6.1978, 6.1949]], requires_grad=True)
tensor([[-0.0068, -0.0068]])
Parameter containing:
tensor([-2.6152], requires_grad=True)
tensor([0.0035])
model(X)
tensor([[0.0682],
[0.9729],
[0.9729],
[0.9999]], grad_fn=<SigmoidBackward0>)
A little neural network: results¶