Week 1 Friday#
Screenshare notes#



Deepnote notebook#
The main goal today is to prepare for Lab 1, which is about automatically decrypting Vigenère ciphertext.
Importing some libraries and functions we will need.
import string
import numpy as np
from Helper3 import (
only_letters,
weave,
shift_string,
kasiski_diffs,
ind_co,
mut_ind_co,
get_freq,
english_freq,
freq_chart
)
Here are three Vigenère ciphertexts. The string
Y0was encrypted using a key length of1, the stringY1was encrypted using a key length of5, and the stringY2was encrypted using a key length of201.
Y0 = '''IWTSX UUXTW TAABP CZTNT MRWPC VTPAV DGXIW BHDAK THIWT UDAAD
LXCVS XATBB PPAXR TPCSQ DQLPC IIDHW PGTPH TRGTI ZTNUD GJHTX
CPHNB BTIGX RRXEW TGQJI IWTXG DCANB TPCHD URDBB JCXRP IXDCX
HXCHT RJGTT KTGNE XTRTD UXCUD GBPIX DCIWP IIWTN TMRWP CVTXH
DQHTG KTSQN IWTXG PSKTG HPGNT KTWDL XHXIE DHHXQ ATUDG PAXRT
PCSQD QIDHW PGTPZ TNLXI WDJIB PZXCV XIPKP XAPQA TIDTK TPIUX
GHIVA PCRTX IPEET PGHIW PIPAX RTPCS QDQUP RTPCX BEDHH XQATI
PHZXI LPHPQ GXAAX PCIXC HXVWI DUSXU UXTPC SWTAA BPCIW PIIWT
SXUUX RJAIN DUIWT SXHRG TITAD VPGXI WBEGD QATBU DGUEE GDKXS
THPED HHXQA THDAJ IXDC'''
Y1 = """SCNWB EARXA DGUFT MFNRX WXQTG FZJEZ NMRMA LNXEO DNCAX EJUEH
VDWZW HGNFF ZVUBV DVWWU NWFTG SOXLA ZMNTL DXAXM JZHYH QPBXB
MVBRF LZCKB BXRIA DMKNM SCNBK NIURF DVWLH EXXFF TIRVT SDXGB
RDWLX BPAXX UZARI HZLXH EDWYH QHJMB NICAT SOQXR DSLAT MBNBL
NWBXK UZMUR SCNBK ZYEXK RVARX UZQHP HNRMI NNBBU KZOHK ZGRVX
ZIMUH AOXLA ZMNTD DTFBM GJDMF ZFRGZ HOJOT HGJUE DOXXO DVCYB
QNCZE ZILXB SVYIX ZMBMA ZOJEB BZJGW AJKYT BZJGB LKXLL HWUXM
ZNTBM VVBTU QDUEB ZICBG RDPAM NAMBY EDNTG CCNEE LVWMA ZOCAX
CDOYB BPUMR NACAX CDBVK DONEH FVABM GHYKH AGNFY NMOII QJEBW
DNJIH RNRUE DNXEN SDXG"""
Y2 = """DRWFU VMGIO NFCHD MNCWD OJPLK IBFWE PHDMJ QNADL QAFUP LPPHZ
AYRJW WVKPD JGEUW YBVKR IUBZF HJWJT SLXUD NDCCB DMKCZ DPKKB
REPBV VJXLK XYYQV QYTEV JKUSK IQBNP DXFJB HETJB YBJHO IYCEJ
TKQKB PMMZI RFNLG QYQIR KOKCA ICQQZ VIVYI WAUNC QRMUW RTLZE
ULCWT HUKZC AQYZM DCYCP RRYGP SGETH GTYOI QWNUT BQNAE LRJGA
LRTFR UHYYK RAKTW YSXQA XINYL SYYVX ULUOU TUBMJ MMWQS PMOXO
KWXDO JWHIC VVLFF ODZLR CJDBS VYDDS ENYXR PGCSF BTCTX WQBSK
BTMLL TNKVW VEMHV RVNWR VNMEQ AWTYC WPZCE LKLYU QMHDU WXGOV
POPPA EGBAW SMCBV YLRFP CSVSW RXTFY SKQHJ UNIHR GHRXB EZBJH
ADEFS VLWLR HJXRN FCIO"""
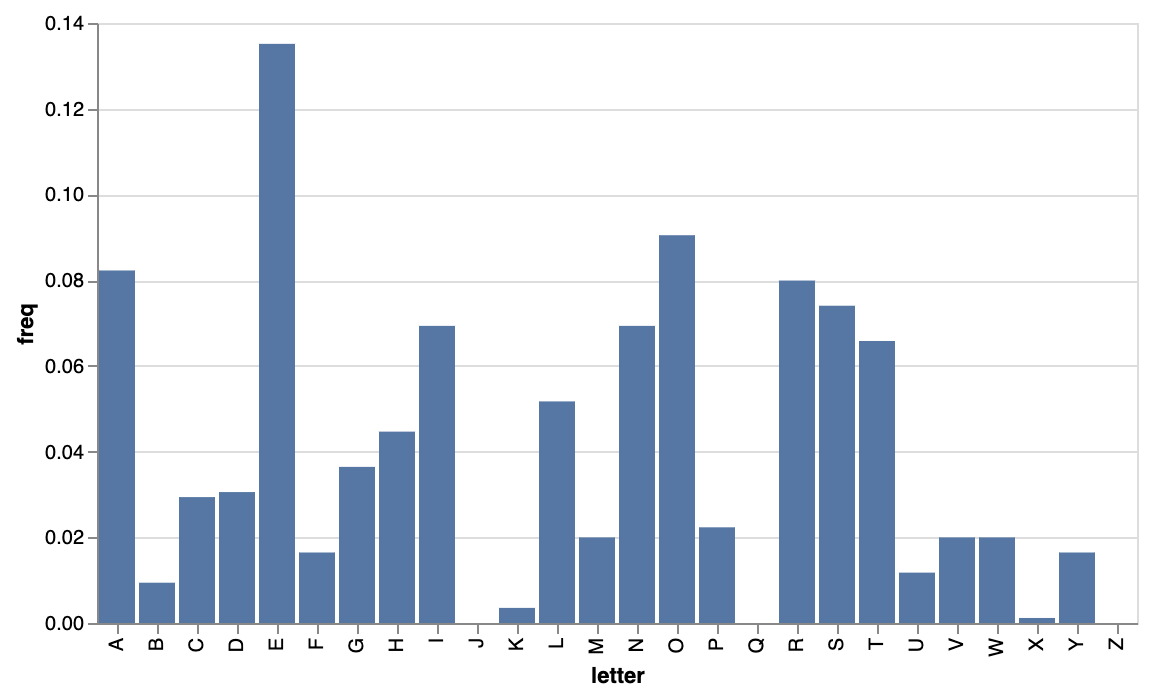
# Looks like a shift cipher
# because Vigenere cipher with key length 1 is the same as a shift cipher
freq_chart(Y0)
1/26
0.038461538461538464
# key length 5
freq_chart(Y1)
# key length 201
freq_chart(Y2)
alt.hconcat(freq_chart(Y1), freq_chart(Y2))
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In [10], line 1
----> 1 alt.hconcat(freq_chart(Y1), freq_chart(Y2))
NameError: name 'alt' is not defined
import altair as alt
alt.hconcat(freq_chart(Y1), freq_chart(Y2))
alt.hconcat(freq_chart(Y1), freq_chart(Y2)).resolve_scale(y="shared")
Approximately how many random repeated trigrams do we expect?
Consider "SCN" from the beginning of Y1. Let’s look at positions 101, 102, 103. What’s the probability that letters 101, 102, 103 are S, C, N, in that order, due to random chance?
1/26**3
5.689576695493855e-05
pow(1/26, 3)
5.689576695493856e-05
len(Y1)
562
only_letters(Y1)
'SCNWBEARXADGUFTMFNRXWXQTGFZJEZNMRMALNXEODNCAXEJUEHVDWZWHGNFFZVUBVDVWWUNWFTGSOXLAZMNTLDXAXMJZHYHQPBXBMVBRFLZCKBBXRIADMKNMSCNBKNIURFDVWLHEXXFFTIRVTSDXGBRDWLXBPAXXUZARIHZLXHEDWYHQHJMBNICATSOQXRDSLATMBNBLNWBXKUZMURSCNBKZYEXKRVARXUZQHPHNRMINNBBUKZOHKZGRVXZIMUHAOXLAZMNTDDTFBMGJDMFZFRGZHOJOTHGJUEDOXXODVCYBQNCZEZILXBSVYIXZMBMAZOJEBBZJGWAJKYTBZJGBLKXLLHWUXMZNTBMVVBTUQDUEBZICBGRDPAMNAMBYEDNTGCCNEELVWMAZOCAXCDOYBBPUMRNACAXCDBVKDONEHFVABMGHYKHAGNFYNMOIIQJEBWDNJIHRNRUEDNXENSDXG'
len(only_letters(Y1))
469
Why is this incorrect: probability of a match is \(1/26^3\), the total length is \(469\), so the expected number of random repetitions should be \(469/26^3\)
469/(26**3)
0.02668411470186618
10 minute break, back at 10:05am
Where did 1/26^3 come from? A random letter is “S” with probability 1/26, is “C” with probability 1/26, …. Because these are independent, the probability of all three happening is \((1/26) \cdot (1/26) \cdot (1/26)\).
How many pairs of slots are there where the repetition could happen (not this particular “SCN” repetition)?
Say we had just 4 possible values, have six possible slots for repetition. n choose 2 (0,1), (0,2), (0,3), (1,2), (1,3), (2,3)
(469*468/2)
109746.0
# Rough estimate: we expect this many repetitions of trigrams due to random chance
(469*468/2) * (1/26**3)
6.244082840236686
kasiski_diffs(Y0)
array([ 10, 10, 12, 15, 15, 15, 16, 23, 23, 23, 23, 24, 26,
29, 33, 33, 33, 42, 46, 49, 56, 56, 57, 58, 58, 65,
65, 66, 66, 69, 69, 69, 74, 75, 75, 77, 77, 77, 77,
77, 77, 77, 77, 77, 78, 80, 81, 87, 87, 89, 90, 90,
90, 107, 107, 107, 107, 107, 107, 112, 112, 112, 112, 112, 112,
119, 120, 133, 133, 134, 136, 136, 144, 147, 149, 160, 168, 170,
171, 171, 171, 171, 171, 171, 171, 171, 174, 179, 180, 180, 180,
180, 180, 180, 184, 184, 184, 184, 184, 184, 184, 184, 184, 186,
187, 196, 196, 197, 197, 202, 206, 210, 211, 211, 211, 211, 211,
211, 217, 219, 219, 219, 219, 219, 219, 226, 226, 236, 248, 252,
261, 261, 261, 261, 261, 261, 261, 261, 261, 266, 271, 271, 276,
277, 277, 287, 287, 292, 292, 317, 317, 318, 320, 320, 332, 332,
346, 355, 370, 374, 374, 374, 374, 377, 377, 377, 377, 377, 380,
396, 396, 396, 397, 397, 397, 397, 397, 397, 412, 412, 412, 425])
# how many repetitions of trigrams in `Y0`
len(kasiski_diffs(Y0))
182
# how many repetitions of trigrams in `Y2`
# This is very close to the amount we would expect due to random chance
len(kasiski_diffs(Y2))
6
# None of these are divisible by the key length of 201
kasiski_diffs(Y2)
array([ 4, 18, 206, 284, 306, 454])
len(kasiski_diffs(Y1))
37
# Notice many of these are divisible by the key length of 5
kasiski_diffs(Y1)
array([ 10, 10, 15, 15, 15, 17, 65, 65, 75, 75, 79, 80, 90,
90, 90, 120, 124, 154, 160, 170, 180, 180, 180, 180, 180, 180,
198, 210, 216, 241, 254, 320, 320, 355, 370, 380, 425])
15%5
0
17%5
2
# how many divisible by 5?
guessed_length = 5
arr = kasiski_diffs(Y1)
t = len(arr)
s = 0 # How many divisible by guessed_length?
for x in arr:
if x%guessed_length == 0: # if x is div by guessed_length
s = s + 1
print(s/t) # if this is a function, use `return`, not `print`
0.7837837837837838
# how many divisible by 7?
guessed_length = 7
arr = kasiski_diffs(Y1)
t = len(arr)
s = 0 # How many divisible by guessed_length?
for x in arr:
if x%guessed_length == 0: # if x is div by guessed_length
s = s + 1
print(s/t) # if this is a function, use `return`, not `print`
0.05405405405405406
Looking for the highest proportion works better for 7-11 than it would for 6-12. Why? Every number divisible by 12 is automatically divisible by 6. So this method would not quite work if the key length were 12 and we tested for divisibility by 6.
Y1
'SCNWB EARXA DGUFT MFNRX WXQTG FZJEZ NMRMA LNXEO DNCAX EJUEH\nVDWZW HGNFF ZVUBV DVWWU NWFTG SOXLA ZMNTL DXAXM JZHYH QPBXB\nMVBRF LZCKB BXRIA DMKNM SCNBK NIURF DVWLH EXXFF TIRVT SDXGB\nRDWLX BPAXX UZARI HZLXH EDWYH QHJMB NICAT SOQXR DSLAT MBNBL\nNWBXK UZMUR SCNBK ZYEXK RVARX UZQHP HNRMI NNBBU KZOHK ZGRVX\nZIMUH AOXLA ZMNTD DTFBM GJDMF ZFRGZ HOJOT HGJUE DOXXO DVCYB\nQNCZE ZILXB SVYIX ZMBMA ZOJEB BZJGW AJKYT BZJGB LKXLL HWUXM\nZNTBM VVBTU QDUEB ZICBG RDPAM NAMBY EDNTG CCNEE LVWMA ZOCAX\nCDOYB BPUMR NACAX CDBVK DONEH FVABM GHYKH AGNFY NMOII QJEBW\nDNJIH RNRUE DNXEN SDXG'
Y = only_letters(Y1)
Y[:20]
'SCNWBEARXADGUFTMFNRX'
Y[0::6]
'SAURGNNCEWZVFLLJPBKASIWFTRPAXHNOLBKSYAHIKGMLDGFJUOQIYMBAZXXMQIPBGLOOMXDVYFIDNXG'
# Chars at position 1 mod 6
# Y[1], Y[7], Y[13], Y[19], ..
Y[1::6]
'CRFXFMXAHHVWTADZBRBDCULFSDARHQIQALUCERPNZRUADJROEDNLIABJJLMVDCAYCVCYRCOAKYQNRE'
print(Y[1], Y[7], Y[13], Y[19])
C R F X
freq_chart(Y[0::6])
freq_chart(Y[1::6])
freq_chart(Y[0::5])
freq_chart(Y[1::5])
freq_chart(Y[2::5])
guessed_length = 6
for i in range(guessed_length):
print(ind_co(Y[i::guessed_length]))
0.03343070431678027
0.04428904428904429
0.05627705627705628
0.056943056943056944
0.038295038295038296
0.04695304695304695
guessed_length = 5
for i in range(guessed_length):
print(ind_co(Y[i::guessed_length]))
0.06680393502630977
0.06131320064058568
0.06154198123999085
0.0581102722489133
0.05586722767648434
# Can't use mutual index of coincidence in this part
# Looks random for these numbers
guessed_length = 5
for i in range(guessed_length):
print(mut_ind_co(get_freq(Y[i::guessed_length]), english_freq))
0.04181702127659574
0.03527340425531914
0.03594468085106382
0.0415936170212766
0.04053763440860215
Use Mutual Index of Coincidence to try to decide if something is English. We use the Index of Coincidence to try to decide if something is shift encrypted or substitution encrypted English. (mut_ind_co wants “E” to be a very common letter. ind_co wants there to be some very common letter, it doesn’t care which it is)
 Created in Deepnote
Created in Deepnote