Week 1 Monday#
Math 173A, Summer Session I Class website
Screenshare notes#

Deepnote notebook#
Motivating questions for today.
Consider the following 20 strings. One of them is shift ciphertext (meaning it was obtained from English by removing spaces and shifting each letter by the same amount), and the rest are random.
NJYJNYMEDBDDAXBTQGIAVQWWJXTTGRECNAOOQSUMPYDY
UOZGXDGBINYGHTYMBJKDSFOTTNPUZRUSNYPSQHSUMXDI
ILTFAEXYJGCAZNRXVILDVSWYFHAQEOJPKBXFKGODOABL
TNFZBAFREIGGDDPGOZVYOFMDSAWTTGDNSJCXAOCEIWPV
UHJIGWXPOVOVIBHWMEHZLAONHJCTIPECKXVGRTGLITQR
BQLTWBLNVTKLWWSZIKWQOFOJFBZLZSIRKJFAHTDTAJIL
ILKWRUXWLZBIURLUPPNZEOSBCSRLPWAXMHJJCTQKJOOZ
PTODVCQAGMGDGQFLLQEXIPKHMZIRYDYTAKWHBZQAOYTD
QRGBYXWPOITKAOMBANEEZJRMVSSFNMEVSGZFTWCFWACH
DAASYKEBEUWTZBFPKLRXZVLCEWSWUQVIRAPUXCTOMPSL
XPPSFVQKLGKPLQRZIWWKGORUKCGPEVFRPZRTEANTVANF
EKICVABHEMRVSKVMMJLYGWCVULRINLOHLRVUKAVFEBWG
HZIIGDICWMRLVRLWYYSXLTRMLJJTPGUNWBDUCHRWNRYX
AWIVDHPKLDSRAKDNXUTYBVNGEGZRYLGDSDHZJIRDQXSG
OWSBYPPVXBATUBEBSJJEHAWPZUKBBYEUGNLDJJVFVIPM
BPIWDCTHTKTCINIWGTTPHJBBTGHTHHXDCDCTJRXGKXCT
WOTMFMEPCWIZLBVZENBDWUUYJVJRBVLQUCMYTEDUFIEU
XOLSJHRDODYQFLSPFHIHZSNXZYFZMZGJNYFWQEPPFHQK
FUTWLMYHFYLHRMIRJOGBDUNTJDGWLDBWRULWDUDHDHBZ
DLSVRDGWWWZNOTLMJRNSCMPMGHCMTUCVCRNPUFIDFDJG
How can we distinguish the ciphertext from the random strings?
Once we’ve identified the ciphertext, how can we recover the original plaintext?
How could we recover the original plaintext automatically?
2+3
5
command-shift-m converts a code cell to a markdown cell (control instead of command on a PC??)
10 minute break until 9:55am#
Try following the lab 0 instructions to create your own Workspace on the Education plan.
# Getting a long string of English text
with open("PridePrejudice.txt", "r") as f:
s = f.read()
type(s)
str
len(s)
748079
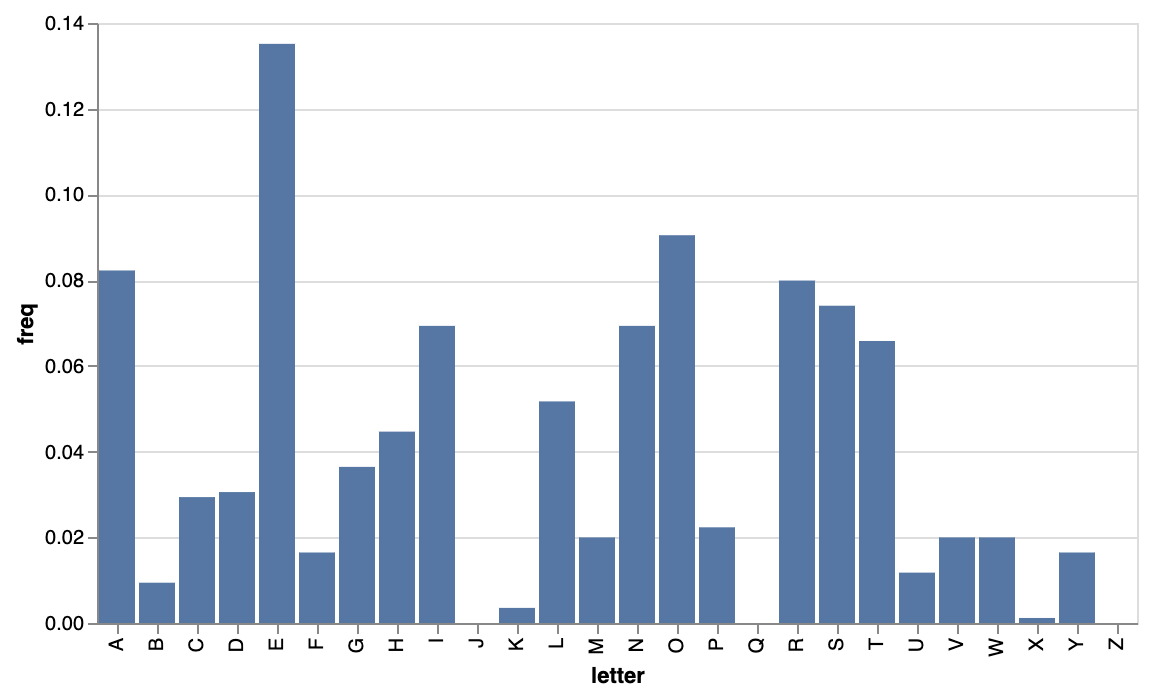
from Helper1 import freq_chart
freq_chart(s)
t = "TNFZBAFREIGGDDPGOZVYOFMDSAWTTGDNSJCXAOCEIWPV"
freq_chart(t)
import numpy as np
import string
rng = np.random.default_rng()
string.ascii_uppercase
'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
list(string.ascii_uppercase)
['A',
'B',
'C',
'D',
'E',
'F',
'G',
'H',
'I',
'J',
'K',
'L',
'M',
'N',
'O',
'P',
'Q',
'R',
'S',
'T',
'U',
'V',
'W',
'X',
'Y',
'Z']
temp = rng.choice(list(string.ascii_uppercase), size=750000)
temp[:10]
array(['T', 'F', 'Y', 'O', 'T', 'B', 'O', 'X', 'B', 'D'], dtype='<U1')
temp = rng.choice(list(string.ascii_uppercase), size=750000)
t2 = ''.join(temp)
t2[:10]
'MAAYFVQJYT'
freq_chart(t2)
1/26
0.038461538461538464
temp = rng.choice(list(string.ascii_uppercase), size=44)
t3 = ''.join(temp)
freq_chart(t3)
# Getting a list of the 20 strings from above
with open("strings20.txt", "r") as f:
lines = f.readlines()
len(lines)
20
lines[3]
'TNFZBAFREIGGDDPGOZVYOFMDSAWTTGDNSJCXAOCEIWPV\n'
import altair as alt
chart_list = []
for line in lines:
chart_list.append(freq_chart(line))
chart_list[3]
alt.vconcat(*chart_list)
t
'TNFZBAFREIGGDDPGOZVYOFMDSAWTTGDNSJCXAOCEIWPV'
from Helper1 import ind_co, get_freq
The ind_co function estimates the index of coincidence. (Warning. It’s not exactly the same as in the textbook.) The index of coincidence gives the probability that two randomly chosen characters are the same character. For random English characters, we expect a probability of about 1/26 approx 0.038. (Higher for shorter strings.) For actual English, we expect a probability of higher, about 0.06.
Textbook/usual definition does random selection without replacement. My function ind_co uses replacement.
get_freq(lines[3])
{'a': 0.06818181818181818,
'b': 0.022727272727272728,
'c': 0.045454545454545456,
'd': 0.09090909090909091,
'e': 0.045454545454545456,
'f': 0.06818181818181818,
'g': 0.09090909090909091,
'h': 0.0,
'i': 0.045454545454545456,
'j': 0.022727272727272728,
'k': 0.0,
'l': 0.0,
'm': 0.022727272727272728,
'n': 0.045454545454545456,
'o': 0.06818181818181818,
'p': 0.045454545454545456,
'q': 0.0,
'r': 0.022727272727272728,
's': 0.045454545454545456,
't': 0.06818181818181818,
'u': 0.0,
'v': 0.045454545454545456,
'w': 0.045454545454545456,
'x': 0.022727272727272728,
'y': 0.022727272727272728,
'z': 0.045454545454545456}
# Higher than 1/26 because our text is short
ind_co(get_freq(lines[3]))
0.05681818181818181
inds = []
for line in lines:
inds.append(ind_co(get_freq(line)))
inds
[0.057851239669421475,
0.05888429752066115,
0.050619834710743786,
0.05681818181818181,
0.055785123966942136,
0.06818181818181818,
0.0568181818181818,
0.055785123966942136,
0.05061983471074378,
0.052685950413223125,
0.06301652892561982,
0.06508264462809916,
0.06198347107438016,
0.06095041322314048,
0.06404958677685947,
0.10020661157024793,
0.06095041322314048,
0.06404958677685949,
0.07541322314049585,
0.06198347107438015]
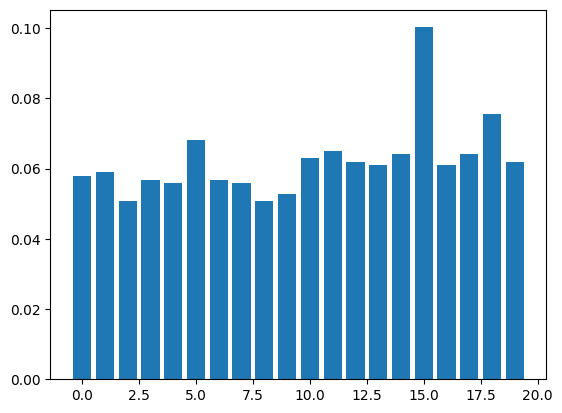
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.bar(range(len(inds)), inds)
<BarContainer object of 20 artists>
import pandas as pd
freq_df = pd.DataFrame({
"number": range(len(inds)),
"index of coincidence": inds
})
freq_df
| number | index of coincidence | |
|---|---|---|
| 0 | 0 | 0.057851 |
| 1 | 1 | 0.058884 |
| 2 | 2 | 0.050620 |
| 3 | 3 | 0.056818 |
| 4 | 4 | 0.055785 |
| 5 | 5 | 0.068182 |
| 6 | 6 | 0.056818 |
| 7 | 7 | 0.055785 |
| 8 | 8 | 0.050620 |
| 9 | 9 | 0.052686 |
| 10 | 10 | 0.063017 |
| 11 | 11 | 0.065083 |
| 12 | 12 | 0.061983 |
| 13 | 13 | 0.060950 |
| 14 | 14 | 0.064050 |
| 15 | 15 | 0.100207 |
| 16 | 16 | 0.060950 |
| 17 | 17 | 0.064050 |
| 18 | 18 | 0.075413 |
| 19 | 19 | 0.061983 |
alt.Chart(freq_df).mark_bar().encode(
x="number:O",
y="index of coincidence",
tooltip=["index of coincidence"]
)
t
'TNFZBAFREIGGDDPGOZVYOFMDSAWTTGDNSJCXAOCEIWPV'
get_freq(t)
{'a': 0.06818181818181818,
'b': 0.022727272727272728,
'c': 0.045454545454545456,
'd': 0.09090909090909091,
'e': 0.045454545454545456,
'f': 0.06818181818181818,
'g': 0.09090909090909091,
'h': 0.0,
'i': 0.045454545454545456,
'j': 0.022727272727272728,
'k': 0.0,
'l': 0.0,
'm': 0.022727272727272728,
'n': 0.045454545454545456,
'o': 0.06818181818181818,
'p': 0.045454545454545456,
'q': 0.0,
'r': 0.022727272727272728,
's': 0.045454545454545456,
't': 0.06818181818181818,
'u': 0.0,
'v': 0.045454545454545456,
'w': 0.045454545454545456,
'x': 0.022727272727272728,
'y': 0.022727272727272728,
'z': 0.045454545454545456}
ind_co(get_freq(t))
0.05681818181818181
c = lines[15]
c
'BPIWDCTHTKTCINIWGTTPHJBBTGHTHHXDCDCTJRXGKXCT\n'
from Helper1 import shift_string
shift_string(c, 0)
'BPIWDCTHTKTCINIWGTTPHJBBTGHTHHXDCDCTJRXGKXCT\n'
shift_string(c, 1)
'CQJXEDUIULUDJOJXHUUQIKCCUHIUIIYEDEDUKSYHLYDU\n'
shift_string(c, 5)
'GUNBIHYMYPYHNSNBLYYUMOGGYLMYMMCIHIHYOWCLPCHY\n'
Notice how “W” shifted by 5 gives us “B”, “WXYZAB”. In terms of the number equivalents: “W” is 22, “B” is 1. 22 + 5 = 27, then we reduce modulo 26 to get 1. If reducing modulo a number is new to you, Byron will introduce/review it in discussion today.
c
'BPIWDCTHTKTCINIWGTTPHJBBTGHTHHXDCDCTJRXGKXCT\n'
c = "BPIWDCTHTKTCINIWGTTPHJBBTGHTHHXDCDCTJRXGKXCT"
How can we decrypt c? In the Lab 0, you will try to automatically decrypt this kind of shift ciphertext.
To get some intuition for this process, try out this app: Streamlit app
Three minutes to try out that app.
for i in range(26):
print(shift_string(c, i))
BPIWDCTHTKTCINIWGTTPHJBBTGHTHHXDCDCTJRXGKXCT
CQJXEDUIULUDJOJXHUUQIKCCUHIUIIYEDEDUKSYHLYDU
DRKYFEVJVMVEKPKYIVVRJLDDVIJVJJZFEFEVLTZIMZEV
ESLZGFWKWNWFLQLZJWWSKMEEWJKWKKAGFGFWMUAJNAFW
FTMAHGXLXOXGMRMAKXXTLNFFXKLXLLBHGHGXNVBKOBGX
GUNBIHYMYPYHNSNBLYYUMOGGYLMYMMCIHIHYOWCLPCHY
HVOCJIZNZQZIOTOCMZZVNPHHZMNZNNDJIJIZPXDMQDIZ
IWPDKJAOARAJPUPDNAAWOQIIANOAOOEKJKJAQYENREJA
JXQELKBPBSBKQVQEOBBXPRJJBOPBPPFLKLKBRZFOSFKB
KYRFMLCQCTCLRWRFPCCYQSKKCPQCQQGMLMLCSAGPTGLC
LZSGNMDRDUDMSXSGQDDZRTLLDQRDRRHNMNMDTBHQUHMD
MATHONESEVENTYTHREEASUMMERSESSIONONEUCIRVINE
NBUIPOFTFWFOUZUISFFBTVNNFSTFTTJPOPOFVDJSWJOF
OCVJQPGUGXGPVAVJTGGCUWOOGTUGUUKQPQPGWEKTXKPG
PDWKRQHVHYHQWBWKUHHDVXPPHUVHVVLRQRQHXFLUYLQH
QEXLSRIWIZIRXCXLVIIEWYQQIVWIWWMSRSRIYGMVZMRI
RFYMTSJXJAJSYDYMWJJFXZRRJWXJXXNTSTSJZHNWANSJ
SGZNUTKYKBKTZEZNXKKGYASSKXYKYYOUTUTKAIOXBOTK
THAOVULZLCLUAFAOYLLHZBTTLYZLZZPVUVULBJPYCPUL
UIBPWVMAMDMVBGBPZMMIACUUMZAMAAQWVWVMCKQZDQVM
VJCQXWNBNENWCHCQANNJBDVVNABNBBRXWXWNDLRAERWN
WKDRYXOCOFOXDIDRBOOKCEWWOBCOCCSYXYXOEMSBFSXO
XLESZYPDPGPYEJESCPPLDFXXPCDPDDTZYZYPFNTCGTYP
YMFTAZQEQHQZFKFTDQQMEGYYQDEQEEUAZAZQGOUDHUZQ
ZNGUBARFRIRAGLGUERRNFHZZREFRFFVBABARHPVEIVAR
AOHVCBSGSJSBHMHVFSSOGIAASFGSGGWCBCBSIQWFJWBS
for i in range(26):
print(ind_co(get_freq(shift_string(c, i))))
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024792
0.10020661157024792
0.10020661157024793
0.10020661157024793
0.10020661157024792
0.10020661157024792
0.1002066115702479
0.1002066115702479
0.1002066115702479
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
0.10020661157024793
Use mutual index of coincidence to compare the shifted text with actual English text.
pride_freq = get_freq(s)
pride_freq
{'a': 0.07739003458965348,
'b': 0.016852962904150066,
'c': 0.02560911620328498,
'd': 0.04094835025994021,
'e': 0.12850815722067646,
'f': 0.022428041783749075,
'g': 0.018998418955958603,
'h': 0.06241671902292859,
'i': 0.07110900918938698,
'j': 0.0017501950414592553,
'k': 0.006035929053237688,
'l': 0.04052029466794623,
'm': 0.02715909169365028,
'n': 0.07022700754620584,
'o': 0.07487693401730174,
'p': 0.015803536291519666,
'q': 0.001139180204500107,
'r': 0.06070449665495267,
's': 0.06161066272671412,
't': 0.0878428759812484,
'u': 0.028141203112378402,
'v': 0.010561581320206296,
'w': 0.022467740487845292,
'x': 0.0017812635924910763,
'y': 0.02344122175350902,
'z': 0.0016759757251054604}
For every possible shift amount, from 0 to 25 (inclusive), we will shift the ciphertext c by that amount, and compute its Mutual Index of Coincidence with the Pride and Prejudice frequencies (representing “average” English). Look for the value that is bigger than the rest.
from Helper1 import mut_ind_co
for i in range(26):
print(i)
print(mut_ind_co(get_freq(shift_string(c,i)), pride_freq))
0
0.043246167741303784
1
0.04032215419918141
2
0.035914421205447224
3
0.034014924515973946
4
0.03205097627429702
5
0.03849248329359278
6
0.03497883415732988
7
0.051290882604184775
8
0.027283287441840613
9
0.02989516403881121
10
0.041080587741667826
11
0.07242973643198718
12
0.041651276227035156
13
0.0282089498139339
14
0.029701377874547075
15
0.04080673729374718
16
0.0338052902524461
17
0.038217181410838595
18
0.03505854538927011
19
0.027886260545262487
20
0.041009428206855034
21
0.041827919769075926
22
0.03544372481172144
23
0.03890833898739119
24
0.04762122383729871
25
0.0388541259349594
shift_string(c, 11)
'MATHONESEVENTYTHREEASUMMERSESSIONONEUCIRVINE'
 Created in Deepnote
Created in Deepnote