
Worksheet 15#
Due Tuesday night (instead of the usual Monday due date), because of the Memorial Day holiday.
The goal of this worksheet is to use a Decision Tree classifier to predict whether or not a passenger of the Titanic survived.
Many of the ideas in this worksheet come from this notebook on Kaggle by ZlatanKremonic. The dataset we use comes from a Kaggle competition.
Feature Engineering#
A few useful columns in this DataFrame are not directly useable as they are, for example because they include missing values or because they are non-numeric. By “Feature Engineering”, we mean adding new columns (or adjusting existing columns) that can be used by our Machine Learning model.
Load the attached Titanic dataset.
Using Boolean indexing, remove the rows where the “Embarked” column value is missing.
Drop the “PassengerId” column using the
dropmethod, withdrop("PassengerId", axis=???). You should probably use thecopymethod to prevent warnings in the next step.Check: at this stage, the DataFrame should have
889rows and11columns.
Add a column “AgeNull” which contains
Trueif the value in the “Age” column is missing and containsFalseotherwise. The code to do this is shorter than you might expect:df["AgeNull"] = df["Age"].isna().
Fill in the missing values in the “Age” column with the median value from that column. Use the pandas Series method
fillna. (Replace the “Age” column with this new column that does not have any missing values.)
Add a column “IsFemale” which contains
Trueif the value in the “Sex” column is"female". (As with the “AgeNull” column above, you shouldn’t need to usemapor a for loop or anything like that.)
Splitting the data with train_test_split#
Make a list
featurescontaining the names of all the numeric columns in the DataFrame except for the “Survived” column. (Use the functionis_numeric_dtypefrompandas.api.types. To take the “Survived” column out of the list, you might want to use the Python list methodremove. Notice thatremovechanges this list in place.)
Check: there should be 7 column names in the
featureslist.
Divide the data into a training set and a test set using
train_test_split. Use the columns named infeaturesfor the input features. For the target, use the “Survived” column. For the size, usetrain_sizeto specify that we should use 60% of the rows for the training set. Name the resulting objectsX_train, X_test, y_train, y_test.
Predicting survival using a decision tree#
Instantiate a
DecisionTreeClassifierobjectclf. Include restrictions on the complexity of the tree using the keyword argumentsmax_leaf_nodesand/ormax_depthwhen you instantiate the classifier.Fit the classifier using
X_trainandy_train.Try to experiment with different values of
max_leaf_nodesand/ormax_depthuntil you have a tree which seems to be performing well (say, over 80% accuracy on the test set, as calculated usingclf.score) and which does not seem to be drastically overfitting the data (say, the accuracy on the training set should be within 5% of the accuracy on the test set).
Warning. Be sure you are never calling the fit method with the test set; you should only use the predict method or the score method with the test set.
Illustrating the decision tree#
Use the following code to visualize how your decision tree is working. (I don’t totally understand how the
figsize=(20,10)code works… feel free to adjust it if other values work better for your particular tree.)
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
fig = plt.figure(figsize=(20,10))
_ = plot_tree(clf, feature_names=clf.feature_names_in_, filled=True)
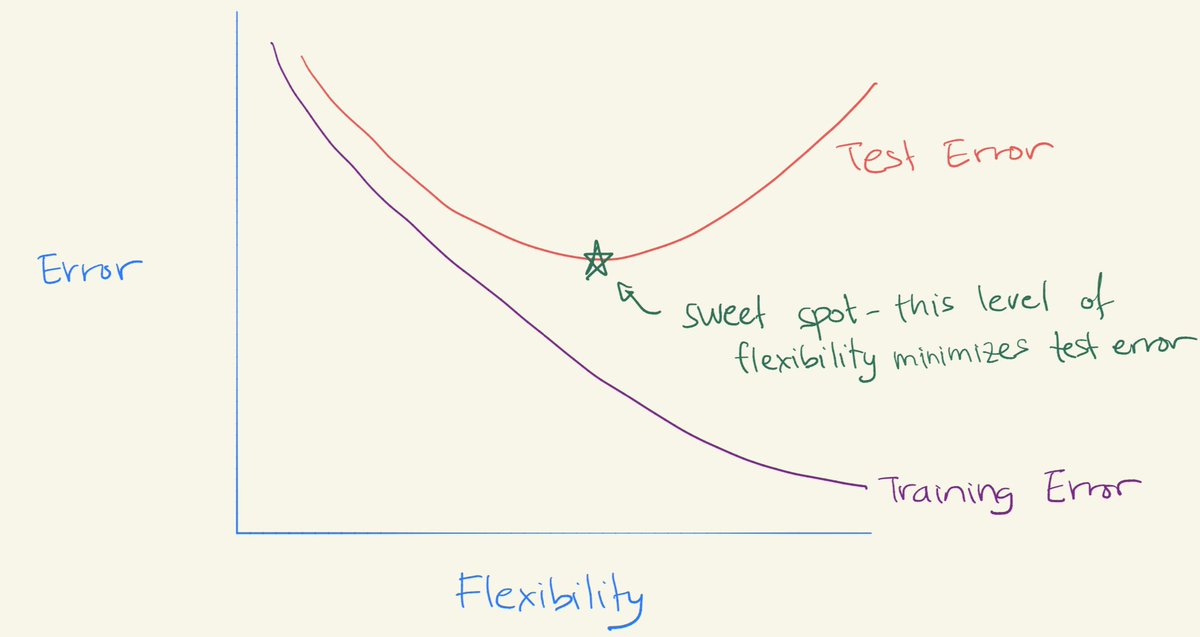
The U-shaped test error curve#
Our last goal in this worksheet is to reproduce a curve like the following, taken from a Twitter post by Daniela Witten. The flexibility axis will correspond to the number of tree leaves. To make this chart using Altair, we will use a DataFrame with rows for training errors and with additional rows for test errors.
Make an empty pandas DataFrame
df_errwith three columns namedleaves,errorandset.
For each integer value i from 2 to 40, inclusive, do the following. (Use a for loop. Our overall goal is to have a row for training error and another row for test error.)
Fit a
DecisionTreeClassifierwithmax_leaf_nodes=ito the training data. (Don’t put a restriction on the depth of the decision tree.)Add a new row to
df_errcontainingifor the value in the “leaves” column, containing the string"train"for the value in the “set” column, and containing the error rate for the value in the “error” column. (For example, if thescoreon the training data is0.82, then you would put0.18for the “error” value.) Suggestion: add this new row by executingdf_err.loc[len(df_err)] = d, wheredis an appropriate Python dictionary.Again do the same thing, this time using the error rate on the test set, and using the string
"test"for the “set” column.
Warning. Be sure you are never fitting a classifier on the test set.
Make an Altair line chart
cusing “leaves” for the x-axis, using “error” for the y-axis, and using “set” for the color. (The result should look approximately like the image above. The image above is an idealized version of how we would expect the training error and test error curves to look. Most “real-world” error curves, including yours, will display more randomness and less regularity than the image above.)
Can you recognize the approximate “U-shape” in the test error curve?
What would you estimate is the “sweet spot” for the ideal level of flexibility for this data? How does it compare to what you chose in the “Predicting survival” section above?
Reminder#
Every group member needs to submit this on Canvas (even if you all submit the same file).
Submission#
Save the resulting Altair chart as a png file (click the three dots at the upper right of the Altair chart) and submit that png file on Canvas.