
Week 8 Videos
Contents
Week 8 Videos¶
import numpy as np
import pandas as pd
import altair as alt
Generating quadratic data¶
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=1000, n_features=1, bias=15, noise=20, random_state=4)
pd.DataFrame({"x":X, "y":y})
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/var/folders/8j/gshrlmtn7dg4qtztj4d4t_w40000gn/T/ipykernel_6239/429307098.py in <module>
----> 1 pd.DataFrame({"x":X, "y":y})
~/miniconda3/envs/math10s22/lib/python3.7/site-packages/pandas/core/frame.py in __init__(self, data, index, columns, dtype, copy)
612 elif isinstance(data, dict):
613 # GH#38939 de facto copy defaults to False only in non-dict cases
--> 614 mgr = dict_to_mgr(data, index, columns, dtype=dtype, copy=copy, typ=manager)
615 elif isinstance(data, ma.MaskedArray):
616 import numpy.ma.mrecords as mrecords
~/miniconda3/envs/math10s22/lib/python3.7/site-packages/pandas/core/internals/construction.py in dict_to_mgr(data, index, columns, dtype, typ, copy)
463
464 return arrays_to_mgr(
--> 465 arrays, data_names, index, columns, dtype=dtype, typ=typ, consolidate=copy
466 )
467
~/miniconda3/envs/math10s22/lib/python3.7/site-packages/pandas/core/internals/construction.py in arrays_to_mgr(arrays, arr_names, index, columns, dtype, verify_integrity, typ, consolidate)
122
123 # don't force copy because getting jammed in an ndarray anyway
--> 124 arrays = _homogenize(arrays, index, dtype)
125
126 else:
~/miniconda3/envs/math10s22/lib/python3.7/site-packages/pandas/core/internals/construction.py in _homogenize(data, index, dtype)
588
589 val = sanitize_array(
--> 590 val, index, dtype=dtype, copy=False, raise_cast_failure=False
591 )
592
~/miniconda3/envs/math10s22/lib/python3.7/site-packages/pandas/core/construction.py in sanitize_array(data, index, dtype, copy, raise_cast_failure, allow_2d)
574 subarr = maybe_infer_to_datetimelike(subarr)
575
--> 576 subarr = _sanitize_ndim(subarr, data, dtype, index, allow_2d=allow_2d)
577
578 if isinstance(subarr, np.ndarray):
~/miniconda3/envs/math10s22/lib/python3.7/site-packages/pandas/core/construction.py in _sanitize_ndim(result, data, dtype, index, allow_2d)
625 if allow_2d:
626 return result
--> 627 raise ValueError("Data must be 1-dimensional")
628 if is_object_dtype(dtype) and isinstance(dtype, ExtensionDtype):
629 # i.e. PandasDtype("O")
ValueError: Data must be 1-dimensional
X.shape
(1000, 1)
X[:10]
array([[-0.20735394],
[ 0.18362632],
[ 0.33825293],
[ 0.28220666],
[-1.3474603 ],
[ 0.54950758],
[ 0.06797219],
[-0.79674267],
[-2.29291305],
[-1.16156742]])
type(X)
numpy.ndarray
X.reshape(-1).shape
(1000,)
df = pd.DataFrame({"x":X.reshape(-1), "y":y})
alt.Chart(df).mark_circle().encode(
x="x",
y="y"
)
df["y"] = df["y"]**2
alt.Chart(df).mark_circle().encode(
x="x",
y="y"
)
df["y"] *= 1/50
alt.Chart(df).mark_circle().encode(
x="x",
y="y"
)
16000/50
320.0
PolynomialFeatures¶
df
| x | y | |
|---|---|---|
| 0 | -0.207354 | 8.283916 |
| 1 | 0.183626 | 2.290559 |
| 2 | 0.338253 | 45.708364 |
| 3 | 0.282207 | 0.594082 |
| 4 | -1.347460 | 2.214989 |
| ... | ... | ... |
| 995 | 0.614307 | 33.987890 |
| 996 | 0.233874 | 16.966095 |
| 997 | 0.050562 | 30.240024 |
| 998 | 2.360360 | 123.332288 |
| 999 | 1.319017 | 101.775461 |
1000 rows × 2 columns
max_deg = 6
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=max_deg, include_bias=False)
poly.fit(df[["x"]])
PolynomialFeatures(degree=6, include_bias=False)
poly.transform(df[["x"]]).shape
(1000, 6)
pd.DataFrame(poly.transform(df[["x"]])).head()
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 0 | -0.207354 | 0.042996 | -0.008915 | 0.001849 | -0.000383 | 0.000079 |
| 1 | 0.183626 | 0.033719 | 0.006192 | 0.001137 | 0.000209 | 0.000038 |
| 2 | 0.338253 | 0.114415 | 0.038701 | 0.013091 | 0.004428 | 0.001498 |
| 3 | 0.282207 | 0.079641 | 0.022475 | 0.006343 | 0.001790 | 0.000505 |
| 4 | -1.347460 | 1.815649 | -2.446515 | 3.296582 | -4.442014 | 5.985437 |
cols = [f"x{i}" for i in range(1,max_deg+1)]
df[cols] = poly.transform(df[["x"]])
df.head()
| x | y | x1 | x2 | x3 | x4 | x5 | x6 | |
|---|---|---|---|---|---|---|---|---|
| 0 | -0.207354 | 8.283916 | -0.207354 | 0.042996 | -0.008915 | 0.001849 | -0.000383 | 0.000079 |
| 1 | 0.183626 | 2.290559 | 0.183626 | 0.033719 | 0.006192 | 0.001137 | 0.000209 | 0.000038 |
| 2 | 0.338253 | 45.708364 | 0.338253 | 0.114415 | 0.038701 | 0.013091 | 0.004428 | 0.001498 |
| 3 | 0.282207 | 0.594082 | 0.282207 | 0.079641 | 0.022475 | 0.006343 | 0.001790 | 0.000505 |
| 4 | -1.347460 | 2.214989 | -1.347460 | 1.815649 | -2.446515 | 3.296582 | -4.442014 | 5.985437 |
Evaluating polynomial regression, Part 1¶
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
X_train, X_test, y_train, y_test = train_test_split(df[cols], df["y"], train_size=20, random_state=0)
for i in range(1,max_deg+1):
reg = LinearRegression()
sub_cols = cols[:i]
print(sub_cols)
['x1']
['x1', 'x2']
['x1', 'x2', 'x3']
['x1', 'x2', 'x3', 'x4']
['x1', 'x2', 'x3', 'x4', 'x5']
['x1', 'x2', 'x3', 'x4', 'x5', 'x6']
train_error_dict = {}
test_error_dict = {}
for i in range(1,max_deg+1):
reg = LinearRegression()
sub_cols = cols[:i]
reg.fit(X_train[sub_cols], y_train)
train_error_dict[i] = mean_squared_error(reg.predict(X_train[sub_cols]), y_train)
test_error_dict[i] = mean_squared_error(reg.predict(X_test[sub_cols]), y_test)
train_error_dict
{1: 273.65221070646004,
2: 174.4690132350938,
3: 171.7311919316596,
4: 171.3812547748483,
5: 109.07647969349776,
6: 106.63430810917487}
test_error_dict
{1: 1585.3912941201534,
2: 1128.0874914175256,
3: 1134.1637387874664,
4: 1190.2283257927493,
5: 13294.49407116664,
6: 18948.061196962655}
Evaluating polynomial regression, Part 2¶
X_train, X_test, y_train, y_test = train_test_split(df[cols], df["y"], train_size=0.8, random_state=0)
X_train.shape
(800, 6)
train_error_dict2 = {}
test_error_dict2 = {}
for i in range(1,max_deg+1):
reg = LinearRegression()
sub_cols = cols[:i]
reg.fit(X_train[sub_cols], y_train)
train_error_dict2[i] = mean_squared_error(reg.predict(X_train[sub_cols]), y_train)
test_error_dict2[i] = mean_squared_error(reg.predict(X_test[sub_cols]), y_test)
train_error_dict2
{1: 1403.2377764663738,
2: 874.9828631207221,
3: 873.8798463724188,
4: 869.1090703099768,
5: 868.526343606727,
6: 866.5825551013062}
test_error_dict2
{1: 1168.3993370294302,
2: 578.2755896285452,
3: 575.291312202487,
4: 586.276780022717,
5: 595.300138775016,
6: 595.6424078820787}
Plotting the test error curve¶
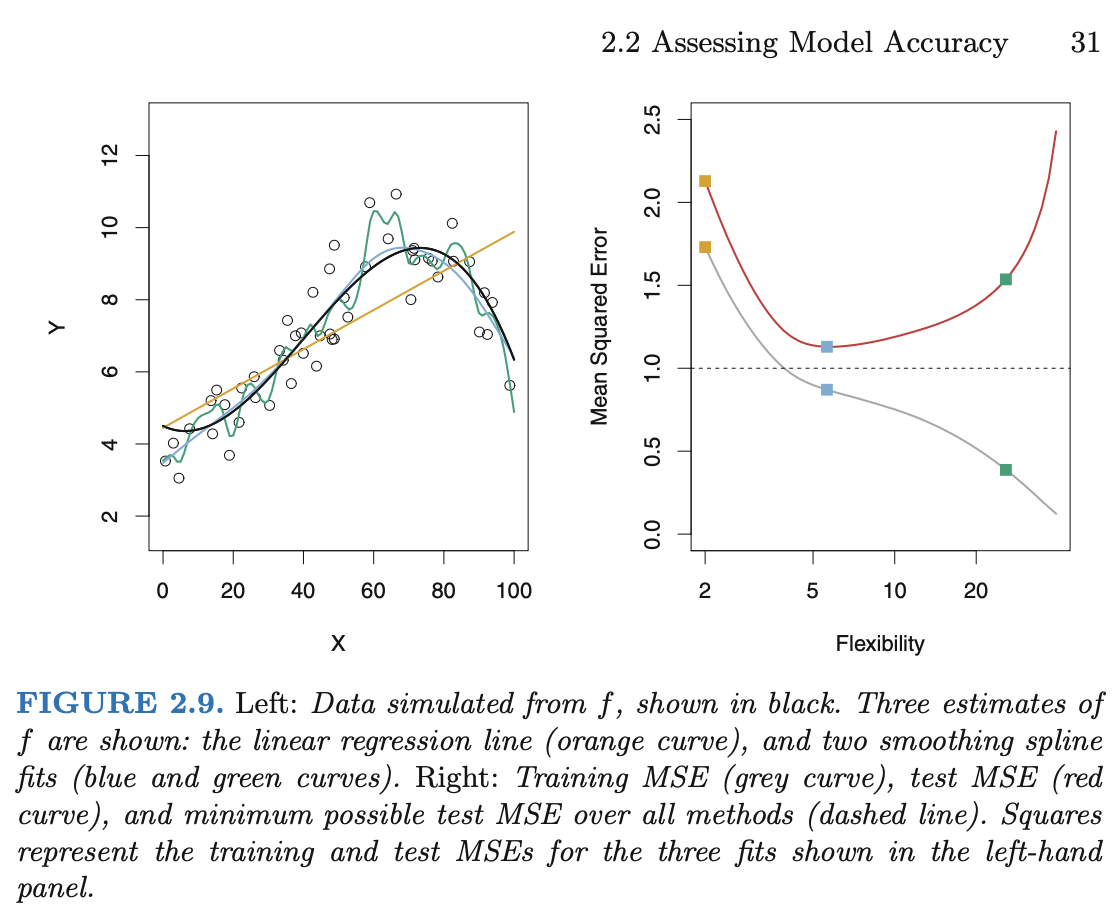 Source: Introduction to Statistical Learning
Source: Introduction to Statistical Learning
df_train = pd.DataFrame({"y":train_error_dict, "type": "train"})
df_test = pd.DataFrame({"y":test_error_dict, "type": "test"})
df_test
| y | type | |
|---|---|---|
| 1 | 1585.391294 | test |
| 2 | 1128.087491 | test |
| 3 | 1134.163739 | test |
| 4 | 1190.228326 | test |
| 5 | 13294.494071 | test |
| 6 | 18948.061197 | test |
df_small = pd.concat([df_train, df_test]).reset_index()
df_small
| index | y | type | |
|---|---|---|---|
| 0 | 1 | 273.652211 | train |
| 1 | 2 | 174.469013 | train |
| 2 | 3 | 171.731192 | train |
| 3 | 4 | 171.381255 | train |
| 4 | 5 | 109.076480 | train |
| 5 | 6 | 106.634308 | train |
| 6 | 1 | 1585.391294 | test |
| 7 | 2 | 1128.087491 | test |
| 8 | 3 | 1134.163739 | test |
| 9 | 4 | 1190.228326 | test |
| 10 | 5 | 13294.494071 | test |
| 11 | 6 | 18948.061197 | test |
alt.Chart(df_small).mark_line(clip=True).encode(
x="index:O",
y=alt.Y("y", scale=alt.Scale(domain=(0,2000))),
color="type"
)
df_train2 = pd.DataFrame({"y":train_error_dict2, "type": "train"})
df_test2 = pd.DataFrame({"y":test_error_dict2, "type": "test"})
df_test2
| y | type | |
|---|---|---|
| 1 | 1168.399337 | test |
| 2 | 578.275590 | test |
| 3 | 575.291312 | test |
| 4 | 586.276780 | test |
| 5 | 595.300139 | test |
| 6 | 595.642408 | test |
df_big = pd.concat([df_train2, df_test2]).reset_index()
alt.Chart(df_big).mark_line(clip=True).encode(
x="index:O",
y=alt.Y("y", scale=alt.Scale(domain=(0,2000))),
color="type"
)