
Week 8 Friday
Contents
Week 8 Friday#
Announcements#
Videos due. Relevant to next week’s Worksheet 15.
Next week’s videos posted. The last video, Evidence of Overfitting 2, might help you understand the U-shaped test error curve better. The video quiz for that video is also a good sample question for next week’s Canvas Quiz.
No discussion section until the strike is resolved.
Course project instructions have been added to the course notes. A “warm-up” homework for the course project is Worksheet 16, posted in the Week 9 folder.
Here is a reference for feature importance on Towards Data Science if you want to see the mathematical details of how the feature importances are calculated.
Canvas quiz for next week#
Based on the Decision Tree and U-shaped test error material (Worksheets 13 and 14 and this week’s lectures).
Counts as an in-class quiz.
Multiple choice or numerical answer (you will probably need to use Python to answer one of the questions).
Open book, open computer.
Can communicate with other students about the questions. (I’d rather not allow this, but I don’t know how to enforce that.)
Time limit of 30 minutes.
Would you rather the quiz be taken between 4-5pm on Tuesday, or taken any time before Tuesday night? Let me know by answering this Ed Discussion poll (the poll closes at 10:30am).
Iris code from Wednesday#
The only change I made was to use X_train, X_test, y_train, y_test instead of df_train, df_test. This will save some typing later.
import pandas as pd
import numpy as np
import seaborn as sns
import altair as alt
from matplotlib import pyplot as plt
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
df = sns.load_dataset("iris")
cols = ["petal_length", "petal_width", "sepal_length"]
X = df[cols]
y = df["species"]
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=2)
Use the following to visualize the data. Last time we used df_train as our dataset, but that doesn’t exist anymore.
alt.Chart(???).mark_circle(size=50, opacity=1).encode(
x="petal_length",
y="petal_width",
color=alt.Color("species", scale=alt.Scale(domain=["versicolor", "setosa", "virginica"])),
)
Here is a reminder of what information is in X_train.
X_train[:3]
| petal_length | petal_width | sepal_length | |
|---|---|---|---|
| 126 | 4.8 | 1.8 | 6.2 |
| 23 | 1.7 | 0.5 | 5.1 |
| 64 | 3.6 | 1.3 | 5.6 |
Notice how y_train corresponds the same index values as X_train.
y_train[:3]
126 virginica
23 setosa
64 versicolor
Name: species, dtype: object
To plot this information using Altair, we need to have something that contains both the numeric values as well as the species value. We could either concatenate X_train and y_train, or we could do the approach below, which is to take the same rows from df using X_train.index.
# Alternative pd.concat([X_train, y_train], axis=1)
df_train = df.loc[X_train.index]
Notice how the index of df_train begins the same. (Slightly confusing: the columns are in a different order. That’s because my cols list changed the order of the columns.)
df_train[:3]
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 126 | 6.2 | 2.8 | 4.8 | 1.8 | virginica |
| 23 | 5.1 | 3.3 | 1.7 | 0.5 | setosa |
| 64 | 5.6 | 2.9 | 3.6 | 1.3 | versicolor |
The following doesn’t work because X_train does not contain the “species” column.
alt.Chart(X_train).mark_circle(size=50, opacity=1).encode(
x="petal_length",
y="petal_width",
color=alt.Color("species", scale=alt.Scale(domain=["versicolor", "setosa", "virginica"])),
)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/vegalite/v4/api.py:2020, in Chart.to_dict(self, *args, **kwargs)
2018 copy.data = core.InlineData(values=[{}])
2019 return super(Chart, copy).to_dict(*args, **kwargs)
-> 2020 return super().to_dict(*args, **kwargs)
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/vegalite/v4/api.py:384, in TopLevelMixin.to_dict(self, *args, **kwargs)
381 kwargs["context"] = context
383 try:
--> 384 dct = super(TopLevelMixin, copy).to_dict(*args, **kwargs)
385 except jsonschema.ValidationError:
386 dct = None
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/utils/schemapi.py:326, in SchemaBase.to_dict(self, validate, ignore, context)
324 result = _todict(self._args[0], validate=sub_validate, context=context)
325 elif not self._args:
--> 326 result = _todict(
327 {k: v for k, v in self._kwds.items() if k not in ignore},
328 validate=sub_validate,
329 context=context,
330 )
331 else:
332 raise ValueError(
333 "{} instance has both a value and properties : "
334 "cannot serialize to dict".format(self.__class__)
335 )
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/utils/schemapi.py:60, in _todict(obj, validate, context)
58 return [_todict(v, validate, context) for v in obj]
59 elif isinstance(obj, dict):
---> 60 return {
61 k: _todict(v, validate, context)
62 for k, v in obj.items()
63 if v is not Undefined
64 }
65 elif hasattr(obj, "to_dict"):
66 return obj.to_dict()
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/utils/schemapi.py:61, in <dictcomp>(.0)
58 return [_todict(v, validate, context) for v in obj]
59 elif isinstance(obj, dict):
60 return {
---> 61 k: _todict(v, validate, context)
62 for k, v in obj.items()
63 if v is not Undefined
64 }
65 elif hasattr(obj, "to_dict"):
66 return obj.to_dict()
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/utils/schemapi.py:56, in _todict(obj, validate, context)
54 """Convert an object to a dict representation."""
55 if isinstance(obj, SchemaBase):
---> 56 return obj.to_dict(validate=validate, context=context)
57 elif isinstance(obj, (list, tuple, np.ndarray)):
58 return [_todict(v, validate, context) for v in obj]
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/utils/schemapi.py:326, in SchemaBase.to_dict(self, validate, ignore, context)
324 result = _todict(self._args[0], validate=sub_validate, context=context)
325 elif not self._args:
--> 326 result = _todict(
327 {k: v for k, v in self._kwds.items() if k not in ignore},
328 validate=sub_validate,
329 context=context,
330 )
331 else:
332 raise ValueError(
333 "{} instance has both a value and properties : "
334 "cannot serialize to dict".format(self.__class__)
335 )
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/utils/schemapi.py:60, in _todict(obj, validate, context)
58 return [_todict(v, validate, context) for v in obj]
59 elif isinstance(obj, dict):
---> 60 return {
61 k: _todict(v, validate, context)
62 for k, v in obj.items()
63 if v is not Undefined
64 }
65 elif hasattr(obj, "to_dict"):
66 return obj.to_dict()
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/utils/schemapi.py:61, in <dictcomp>(.0)
58 return [_todict(v, validate, context) for v in obj]
59 elif isinstance(obj, dict):
60 return {
---> 61 k: _todict(v, validate, context)
62 for k, v in obj.items()
63 if v is not Undefined
64 }
65 elif hasattr(obj, "to_dict"):
66 return obj.to_dict()
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/utils/schemapi.py:56, in _todict(obj, validate, context)
54 """Convert an object to a dict representation."""
55 if isinstance(obj, SchemaBase):
---> 56 return obj.to_dict(validate=validate, context=context)
57 elif isinstance(obj, (list, tuple, np.ndarray)):
58 return [_todict(v, validate, context) for v in obj]
File ~/miniconda3/envs/math10f22/lib/python3.9/site-packages/altair/vegalite/v4/schema/channels.py:40, in FieldChannelMixin.to_dict(self, validate, ignore, context)
38 elif not (type_in_shorthand or type_defined_explicitly):
39 if isinstance(context.get('data', None), pd.DataFrame):
---> 40 raise ValueError("{} encoding field is specified without a type; "
41 "the type cannot be inferred because it does not "
42 "match any column in the data.".format(shorthand))
43 else:
44 raise ValueError("{} encoding field is specified without a type; "
45 "the type cannot be automatically inferred because "
46 "the data is not specified as a pandas.DataFrame."
47 "".format(shorthand))
ValueError: species encoding field is specified without a type; the type cannot be inferred because it does not match any column in the data.
alt.Chart(...)
Notice the three red virginica points in the right center. Those three showed up in our computation from Wednesday, where we computed the probability of a flower being versicolor as 41/44; the difference 3/44 is those three points.
alt.Chart(df_train).mark_circle(size=50, opacity=1).encode(
x="petal_length",
y="petal_width",
color=alt.Color("species", scale=alt.Scale(domain=["versicolor", "setosa", "virginica"])),
)
Create an instance of a DecisionTreeClassifier and set random_state=1, then fit the classifier.
clf = DecisionTreeClassifier(max_leaf_nodes=3, random_state=1)
Fit the classifier to the training data.
clf.fit(X_train, y_train) # never fit using the test data
DecisionTreeClassifier(max_leaf_nodes=3, random_state=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeClassifier(max_leaf_nodes=3, random_state=1)
Illustrate the resulting tree using the following.
fig = plt.figure()
_ = plot_tree(clf,
feature_names=clf.feature_names_in_,
class_names=clf.classes_,
filled=True)
In the following, we can see the same 3 number in the lower-left square. (The classes are always ordered alphabetically, so in this case it goes, setosa, versicolor, virginica.)
fig = plt.figure()
_ = plot_tree(clf,
feature_names=clf.feature_names_in_,
class_names=clf.classes_,
filled=True)
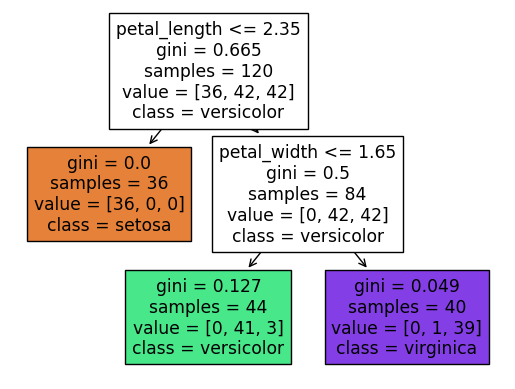
Here is a sample iris (definitely not from the actual dataset, because its petal width is negative) that we can evaluate the classifier on.
df_mini = pd.DataFrame([{"petal_length": 4, "petal_width": -5, "sepal_length": 3}])
df_mini
| petal_length | petal_width | sepal_length | |
|---|---|---|---|
| 0 | 4 | -5 | 3 |
clf.predict(df_mini)
array(['versicolor'], dtype=object)
clf.classes_
array(['setosa', 'versicolor', 'virginica'], dtype=object)
For computing log loss below, it is not enough to know not just the class prediction, but also the predicted probabilities. For example, we need to have a way to distinguish probabilities like [0.34, 0.33, 0.33] from [1, 0, 0]. If we were just using clf.predict, rather than clf.predict_proba, we would not be able to differentiate these values.
clf.predict_proba(df_mini)
array([[0. , 0.93181818, 0.06818182]])
The U-shaped test error curve#
Most of the above material was review from Wednesday. New material for Friday starts here.
We haven’t used the test set so far. Here we will. We will use a loss function that is commonly used for classification problems, log loss (also called cross entropy). If you want to see the mathematical description, I have it in the Spring 2022 course notes, but for us the most important thing is that lower values are better (as with Mean Squared Error and Mean Absolute Error) and that this is a loss function for classification (not for regression).
The score value is too coarse of an estimate. (It is also not a “loss”, because with score, bigger values are better, but for loss/cost/error functions, smaller values are better.)
This score, which records what proportion were correct, does not make sense for regression problems, because asking for our predicted real number to be exactly equal to the true real number is too extreme of a requirement.
clf.score(X_train, y_train)
0.9666666666666667
Define two empty dictionaries,
train_dictandtest_dict.
For each integer value of n from 2 to 9 (inclusive), do the following.
Instantiate a new
DecisionTreeClassifierusingmax_leaf_nodesasnand usingrandom_state=1.Fit the classifier.
Using
log_lossfromsklearn.metrics, evaluate the log loss (error) betweeny_trainand the predicted probabilities. (These two objects need to be input tolog_lossin that order, with the true values first, followed by the predicted probabilities.) Put this error as a value into thetrain_dictdictionary with the keyn.Do the same thing with the test set.
from sklearn.metrics import log_loss
As n increases, the decision tree model becomes more flexible (more complex), and there is more risk of overfitting.
train_dict = {}
test_dict = {}
for n in range(2,10):
clf = DecisionTreeClassifier(max_leaf_nodes=n, random_state=1)
clf.fit(X_train, y_train)
train_error = log_loss(y_train, clf.predict_proba(X_train))
train_dict[n] = train_error
test_error = log_loss(y_test, clf.predict_proba(X_test))
test_dict[n] = test_error
Notice how the following values are decreasing. That is typical: as the model becomes more flexible, the train error decreases. (That is guaranteed with something like Mean Squared Error for regression, provided the model was fit using Mean Squared Error. It is not guaranteed with log loss in this case, because log loss is not used directly when fitting the classifier. But I don’t think I’ve ever seen an example where the log loss increases as the model becomes more flexible.)
train_dict
{2: 0.48520302639196294,
3: 0.13023605214186612,
4: 0.05771345453313897,
5: 0.038968949712512066,
6: 0.018744504820629018,
7: 0.011552453009334511,
8: 2.1094237467877998e-15,
9: 2.1094237467877998e-15}
With the test error, the situation is very different. The test error will typically decrease at first, but then it will usually eventually start increasing. The model performs worse on new data as the model starts to overfit the training data. This shape of decreasing error followed by increasing error is what leads to the characteristic U-shaped test error curve. (See the Wednesday notes for an illustration, or see the end result of Worksheet 14, or see the “Evidence of overfitting 2” video from next week.)
test_dict
{2: 0.36967849629863886,
3: 0.23486681419172778,
4: 0.13845953941519323,
5: 1.2801626834971565,
6: 2.3025850929940472,
7: 2.3025850929940472,
8: 2.3025850929940472,
9: 2.3025850929940472}
How do the values in
train_dictandtest_dictcompare?At what point does the classifier seem to begin overfitting the data?
In this particular case, the overfitting seems to begin when we reach 5 leaf nodes.
clf = DecisionTreeClassifier(max_leaf_nodes=6, random_state=1)
clf.fit(X_train, y_train)
DecisionTreeClassifier(max_leaf_nodes=6, random_state=1)
fig = plt.figure(figsize=(20,10))
_ = plot_tree(clf,
feature_names=clf.feature_names_in_,
class_names=clf.classes_,
filled=True)
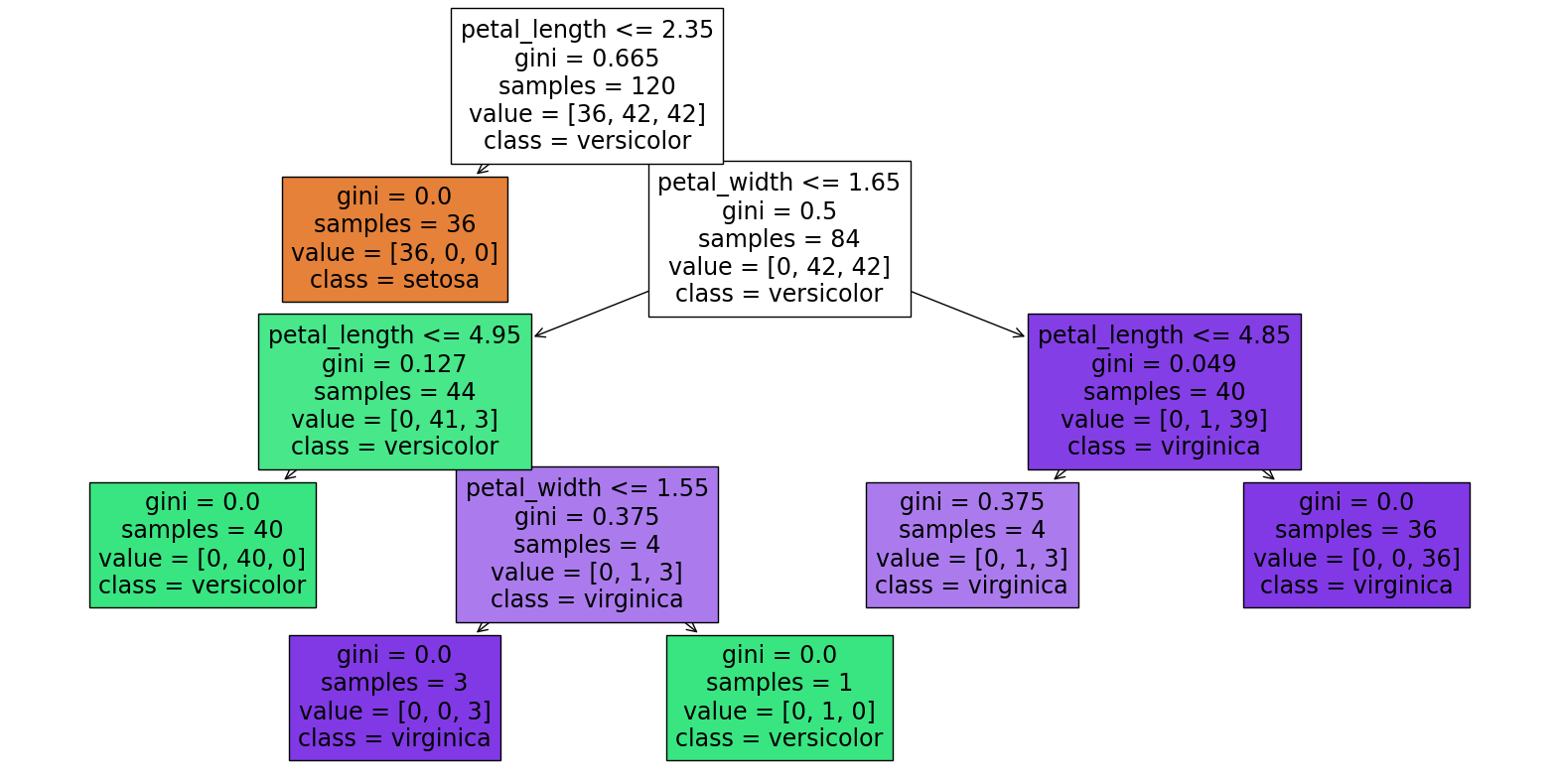
Notice in the above diagram how there is only one section which is not “perfect”, the [0, 1, 3] section near the bottom right. (Perfect means the region contains only one species of iris.) So if we add another leaf node, that is where it will occur.
clf = DecisionTreeClassifier(max_leaf_nodes=7, random_state=1)
clf.fit(X_train, y_train)
DecisionTreeClassifier(max_leaf_nodes=7, random_state=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeClassifier(max_leaf_nodes=7, random_state=1)
fig = plt.figure(figsize=(20,10))
_ = plot_tree(clf,
feature_names=clf.feature_names_in_,
class_names=clf.classes_,
filled=True)
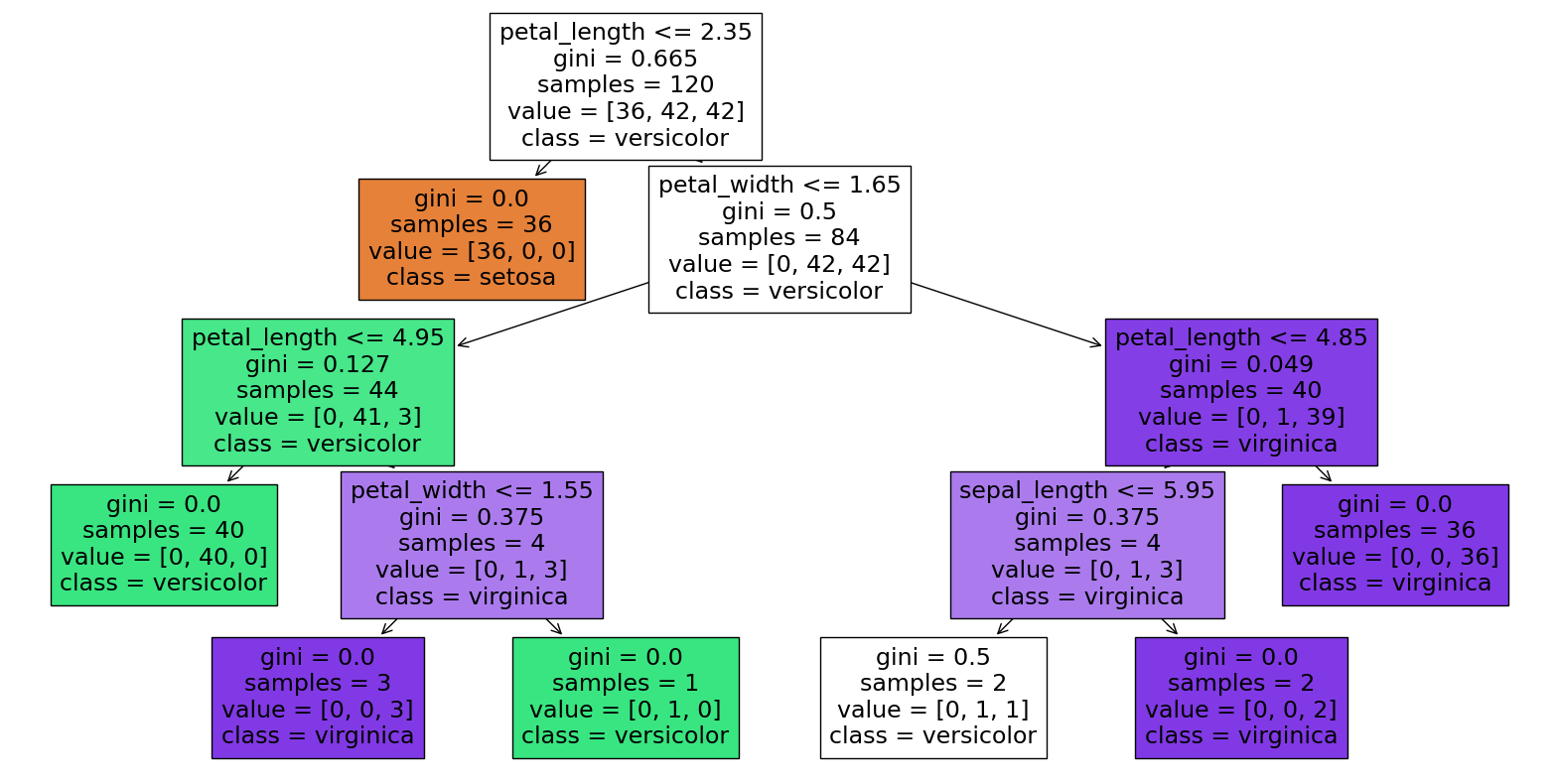
The above is also the first time we have seen the “sepal_length” column get used. It is far less important in this model than the other two features we used, and that is reflected in the feature_importances_ attribute.
Even if you’re not so interested in flowers, when you try making this sort of computation with a dataset you’re more interested in, it can be very interesting to see what the most important columns are.
pd.Series(clf.feature_importances_, index=clf.feature_names_in_)
petal_length 0.537321
petal_width 0.456334
sepal_length 0.006345
dtype: float64
In this last part, we quickly raced through an example of plotting the different prediction regions for this 7-leaf model.
rng = np.random.default_rng(seed=0)
The following will correspond to 5000 irises. We have three columns because clf was fit using three features.
arr = rng.random(size=(5000, 3))
The values in arr are currently between 0 and 1. We rescale two of the columns to correspond to possible values of petal length and petal width. We set the sepal length column to be the constant value 10. (Our Altair chart will not directly show sepal length, so we want the sepal length to be the same for all 5000 flowers.)
arr[:,0] *= 7
arr[:,1] *= 2.5
arr[:,2] = 10
We now convert arr to a pandas DataFrame and give it the appropriate column names.
df_art = pd.DataFrame(arr, columns=clf.feature_names_in_)
We also need a “species” value for each flower. We get this using clf.predict. Note: It is a little risky to have df_art on both the left and right side in the following cell. If we evaluate it twice, it will break. If I had been going more slowly, I would have done the following, which is safer.
df_art["species"] = clf.predict(df_art[cols])
df_art["species"] = clf.predict(df_art)
The following picture looks a little strange. The more complicated these boundaries, the more likely we are to be overfitting the data.
alt.Chart(df_art).mark_circle(size=50, opacity=1).encode(
x="petal_length",
y="petal_width",
color=alt.Color("species", scale=alt.Scale(domain=["versicolor", "setosa", "virginica"])),
)