
Week 8 Videos
Contents
Week 8 Videos#
Downloading the MNIST dataset of handwritten digits#

Source: medium.com
Find the dataset name on openml.org and load it into the notebook using the
fetch_openmlfunction from scikit-learn’sdatasetsmodule. (Warning. I tried loading this dataset twice and ran out of memory, so only run the code once.)
from sklearn.datasets import fetch_openml
mnist = fetch_openml("mnist_784")
type(mnist)
sklearn.utils.Bunch
dir(mnist)
['DESCR',
'categories',
'data',
'details',
'feature_names',
'frame',
'target',
'target_names',
'url']
dfX = mnist.data
type(dfX)
pandas.core.frame.DataFrame
dfX.shape
(70000, 784)
dfX.iloc[4]
pixel1 0.0
pixel2 0.0
pixel3 0.0
pixel4 0.0
pixel5 0.0
...
pixel780 0.0
pixel781 0.0
pixel782 0.0
pixel783 0.0
pixel784 0.0
Name: 4, Length: 784, dtype: float64
arr = dfX.iloc[4].to_numpy()
arr.shape
(784,)
arr2d = arr.reshape((28,28))
arr2d.shape
(28, 28)
import matplotlib.pyplot as plt
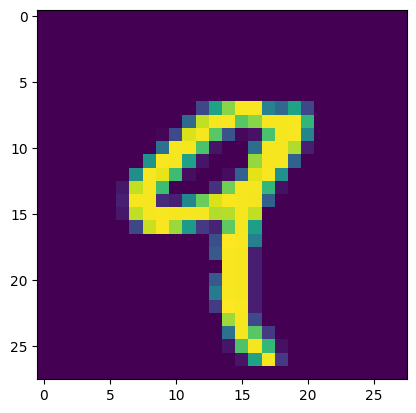
fig, ax = plt.subplots()
ax.imshow(arr2d)
<matplotlib.image.AxesImage at 0x7f71630b4450>
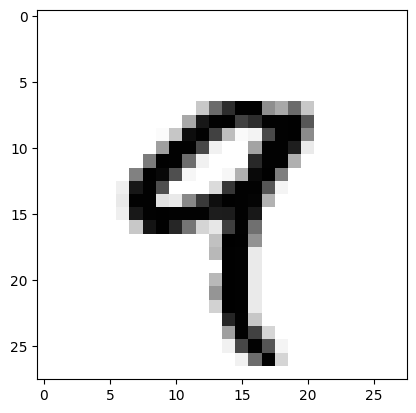
fig, ax = plt.subplots()
ax.imshow(arr2d, cmap='binary')
<matplotlib.image.AxesImage at 0x7f71a96c2410>
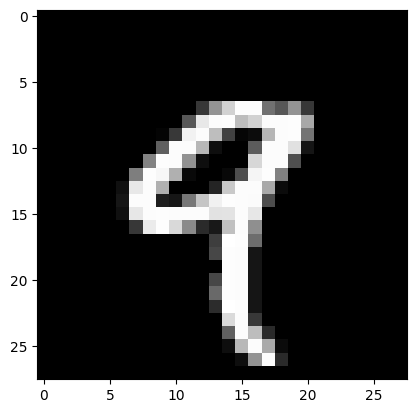
fig, ax = plt.subplots()
ax.imshow(arr2d, cmap='binary_r')
<matplotlib.image.AxesImage at 0x7f71a96c2890>
y = mnist.target
type(y)
pandas.core.series.Series
y.iloc[4]
'9'
Divide the data into a training set and a test set, using 90% of the samples for the training set.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(dfX, y, train_size=0.9)
X_train.shape
(63000, 784)
y_train.shape
(63000,)
X_test.shape
(7000, 784)
Bad idea: Using linear regression with MNIST#
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)
LinearRegression()
reg.predict(X_train)
array([1.57972661, 3.96426198, 4.30633978, ..., 2.12751007, 5.70961828,
4.17563757])
z = reg.predict(X_train).round()
z
array([2., 4., 4., ..., 2., 6., 4.])
y_train
35538 1
34065 5
44649 6
39015 5
56381 7
..
29040 1
57941 3
26295 1
56550 4
54603 3
Name: class, Length: 63000, dtype: category
Categories (10, object): ['0', '1', '2', '3', ..., '6', '7', '8', '9']
y_train == 1
35538 False
34065 False
44649 False
39015 False
56381 False
...
29040 False
57941 False
26295 False
56550 False
54603 False
Name: class, Length: 63000, dtype: bool
y_train == '1'
35538 True
34065 False
44649 False
39015 False
56381 False
...
29040 True
57941 False
26295 True
56550 False
54603 False
Name: class, Length: 63000, dtype: bool
y2 = y_train.astype(int)
y2 == 1
35538 True
34065 False
44649 False
39015 False
56381 False
...
29040 True
57941 False
26295 True
56550 False
54603 False
Name: class, Length: 63000, dtype: bool
y2 == z
35538 False
34065 False
44649 False
39015 False
56381 False
...
29040 True
57941 False
26295 False
56550 False
54603 False
Name: class, Length: 63000, dtype: bool
(y2 == z).mean()
0.22885714285714287
Using a decision tree with MNIST#
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
DecisionTreeClassifier()
z = clf.predict(X_train)
z
array(['1', '5', '6', ..., '1', '4', '3'], dtype=object)
(z == y_train).mean()
1.0
z2 = clf.predict(X_test)
(z2 == y_test).mean()
0.8792857142857143
 Created in Deepnote
Created in Deepnote